分享嘉宾袁鹏,一页科技架构师
君润人力成立于 2019 年,是一家以科技驱动的人力资源解决方案服务商,依托行业领先的科技水平和服务能力,专注于为客户提供一站式人力资源服务。自研数十家人力资源服务平台,深度链接 B 端企业和 C 端用户,构建数字化人力资源服务生态。
本文从君润人力业务快速扩张的背景入手,重点介绍开源 API 网关 APISIX 对其自研平台系统架构的多样化应用场景支持,共有四大线上实战案例,希望对仍在网关选型过程中的企业或用户有所帮助。
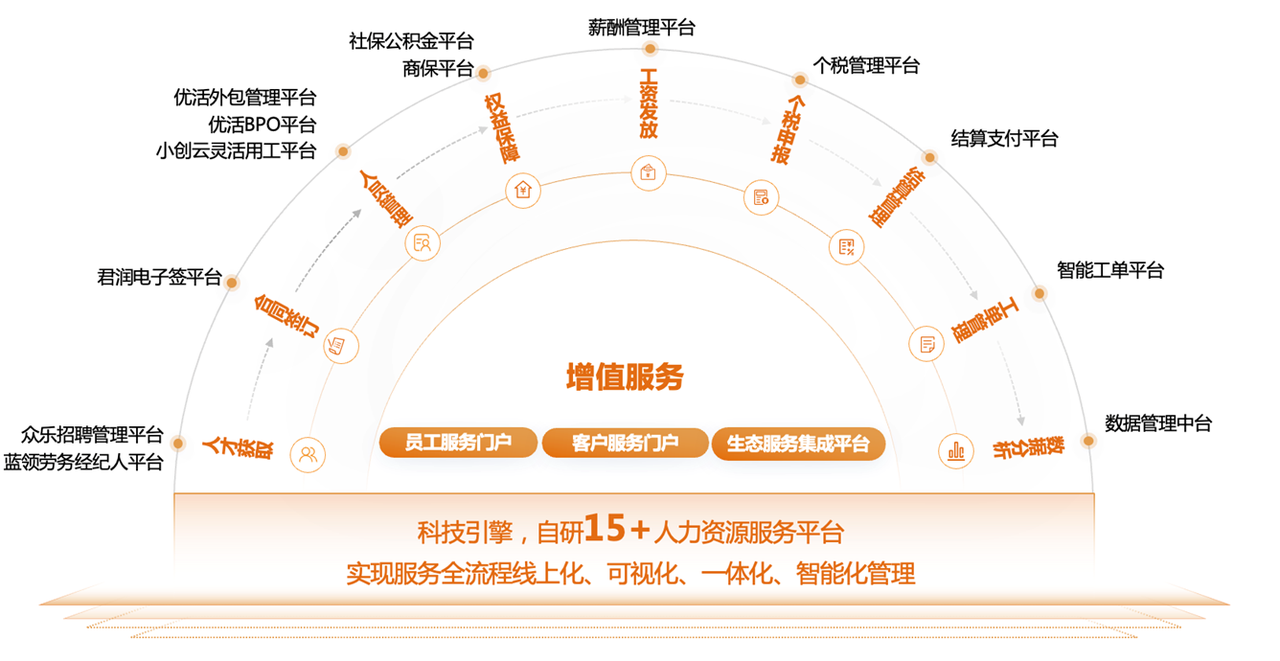
君润人力自研系统架构概述
君润人力在搭建自研服务平台架构时,首要原则就是“开放、开源、拥抱云原生”。平台基于 K8s 微服务架构构建云端系统,整体架构参考下图。
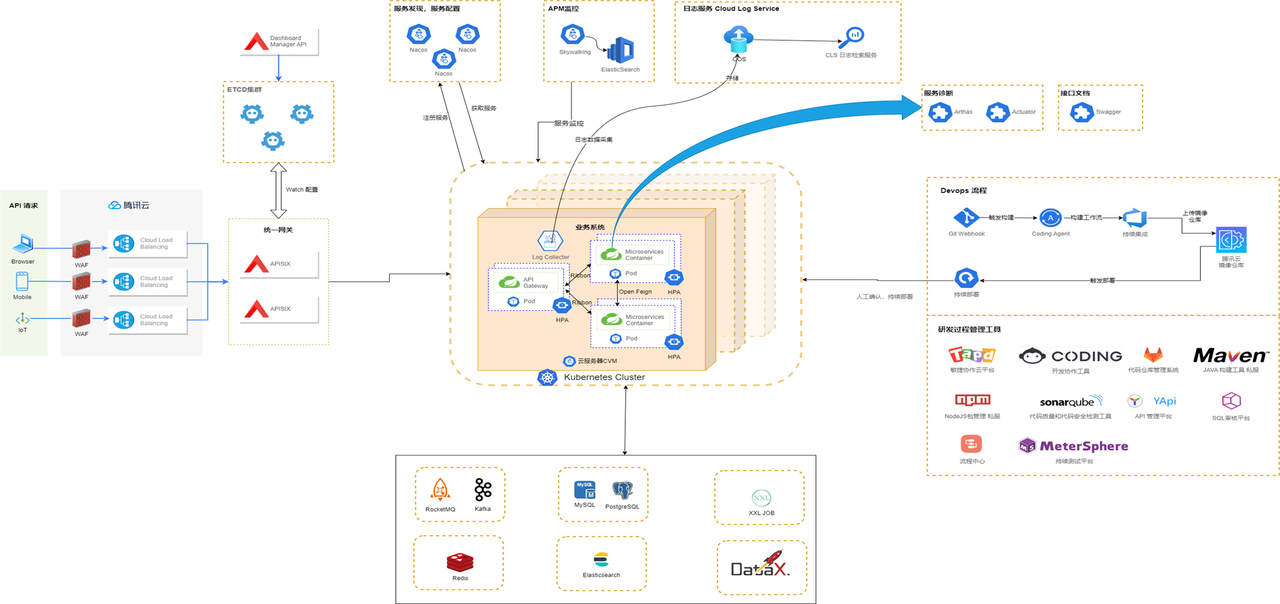
可以看到,君润自研服务平台 DevOps 流程(右侧)依托 Git webhook、coding、K8s 集群实现全自动化与无感发布,业务系统基于 PaaS 平台进行迭代开发,确保研发规范,并达成技术栈的统一。(上侧)在监控手段上,系统集成了 sky-agent 和 arthas,满足了线上服务观测多维度的需求。与此同时,采用腾讯日志云与 K8s 结合的方式将服务日志存储在云上,实现 K8s 集群内无文件化服务,避免磁盘容量堆积从而影响到 K8s 集群单个节点的健康。
架构图的左侧,是业务系统中最重要的环节 -- 流量管理。所有流量会通过 WAF(WAF,Web应用防火墙,负责网络安全)进入三层网络里面的第一层 CLB,它主要负责流量的转发;第二层就是云原生网关 APISIX,它承担了业务系统的内部服务治理;第三层则是业务系统的 Gateway 应用内部的网关,负责单系统鉴权和路由。
其中第一层的 CLB 和第二层的 APISIX 尤其重要,它是所有系统的入口,一旦出现问题,那么所有系统将无法被访问。CLB 采用的是腾讯云服务,稳定性、扩展性与抗并发性能都比较高,业务架构需要解决的是第二层云原生网关 APISIX,保证它的高可用。
APISIX-Service 被部署在 K8s 集群内部,K8s 集群采用的是腾讯云提供的服务,为了保证出现问题后能够快速恢复,系统外置了 etcd 集群,使数据得以保留,这是 APISIX 集群高可用的体现。
那么,如何来保证 APISIX 的高并发和高性能?这里系统利用了 K8s 的机制,当 APISIX 进行路由转发时,通过 K8s 的服务名 + 服务端口使它在同一个网段内跳转;因为网关服务部署在 K8s 内部,依托于 K8s 的特性,可以进行滚动升级,进而达到 APISIX 网关升级的无感发布。
通过该架构图不难发现,第二层是所有流量的入口,选择一个满足业务扩张需求的云原生网关,对我们来说至关重要,下面谈谈在网关技术选型时的主要思考。
技术网关选型痛点
数量庞大的业务系统。我们在人力资源这个领域有 15+ 服务平台,生态业务多样化,面临的问题也比较多,服务请求需要频繁变更,导致需要操作和配置的路由也非常多。原来我们是基于 CLB 进行流量转发,久而久之,运维人员需要配置和操作的地方非常多,耗费了大量的人力与时间。
频繁的高并发大流量。举个例子,客户集中在同一天发薪或提现大额资金。在用户数量达到大几十万时,集中进行的某些行为,如打卡、签约、领取任务或工资等,此时系统并发流量非常大,短期翻倍的情况比比皆是。
个性化需求的扩张压力。APISIX 是基于 OpenResty、Nginx 和 Lua 开发的,但如果用 Lua 来开发插件,会有一定的研发投入和维护成本。
对于插件这块,APISIX 已经提前做好了准备。APISIX 的官网提供了自定义插件 ext-plugin 来支持 Java 开发,我们的技术栈问题恰好迎刃而解。此外 APISIX 的生态非常好,作为国产网关产品,社区极其活跃,业内实践还特别多,在云原生网关这层来说,业内也是顶级存在。
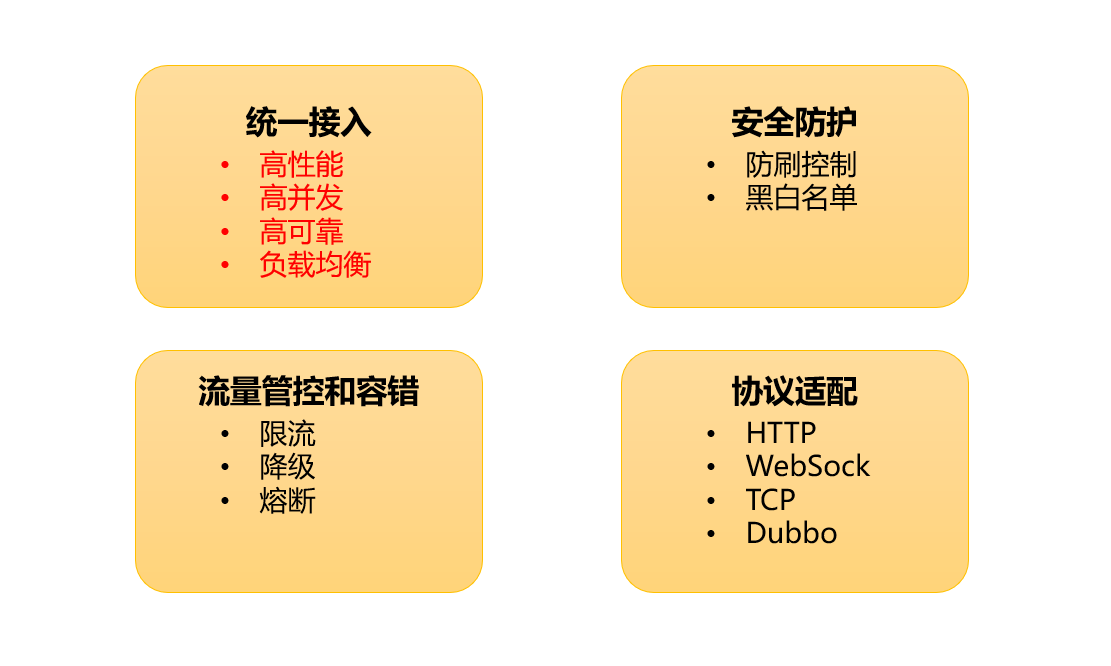
我们的团队非常开放,当我们做完技术选型后,快速实践落地,从上线部署到服务分批次接入,耗时不到 1 个月时间,我们目前 99% 的服务都是通过 APISIX 访问,上线一年多至今零事故,稳定性非常好。下面这张图里,大家能看到 APISIX 的一些特性,其中红字部分是我们最看重的点。
APISIX 四大实践场景
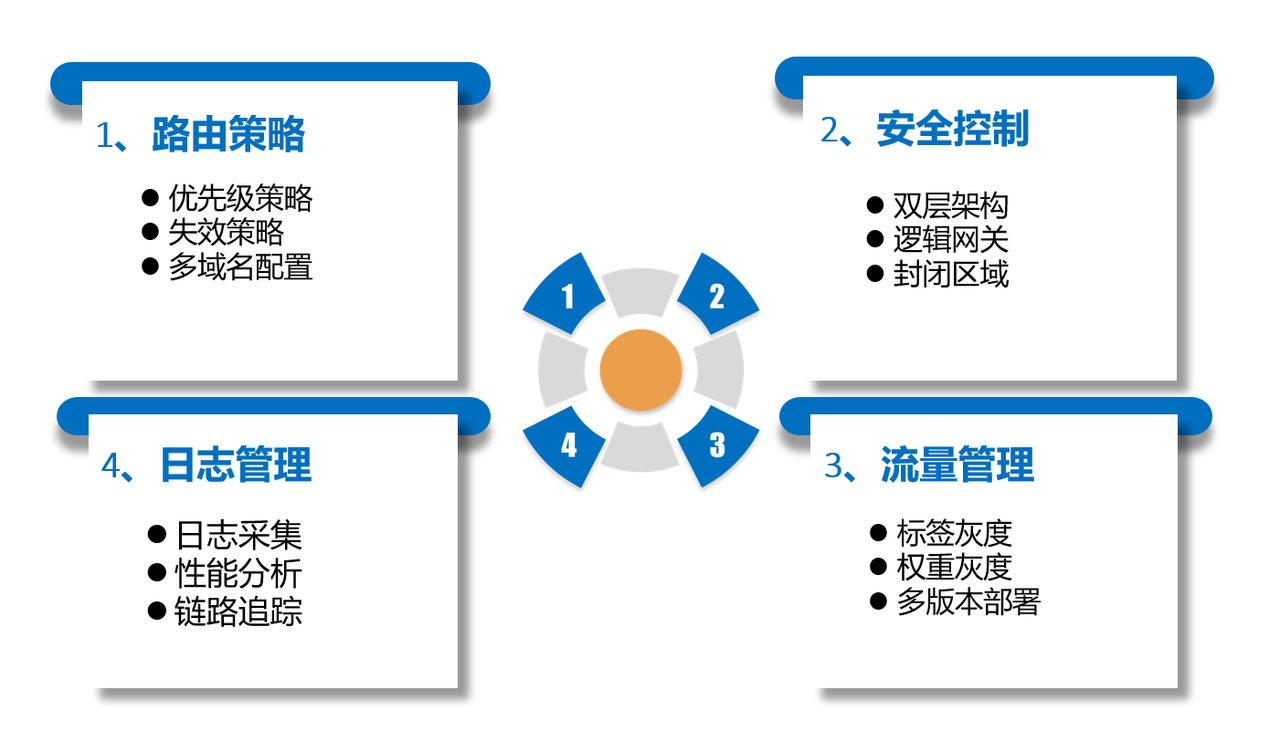
路由策略
Apache APISIX 基于 Radixtree 和 etcd 提供路由极速匹配与配置快速同步的能力。路由和插件的设计实现都满足了极速性能和超低延迟的需求。比如以下两个场景中,都表现出了不错的性能:
业务系统处在高峰期时,用户导出百万数量级的报表数据,会使 MySQL 数据库直接宕机,此时重启服务也无法解决,用户继续导出操作会持续故障,这个问题以前我们得发版才能解决;而现在只需要运维人员简单配置一番,就可以做到 API 紧急停用,通过路由优先级策略和失效策略(依托 Serverless 插件),配合使 API 接口在分钟级下线,从而保证服务的稳定。
我们业务系统非常多,其中 SaaS 系统需要支持客户自定义域名访问,我们采用了泛域名匹配,做到一次配置,全局通用。
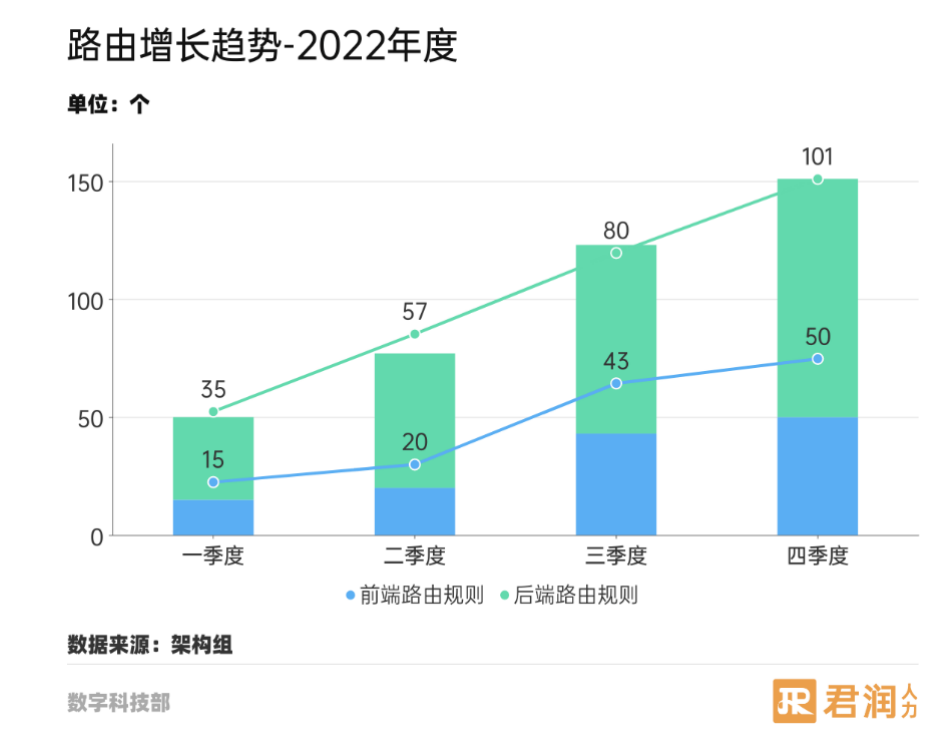
下图是君润人力 2022 全年度路由增长趋势图,可以看到,不论前端还是后端路由,在引入 APISIX 之后,都实现了三倍或以上的数量增长。
安全控制
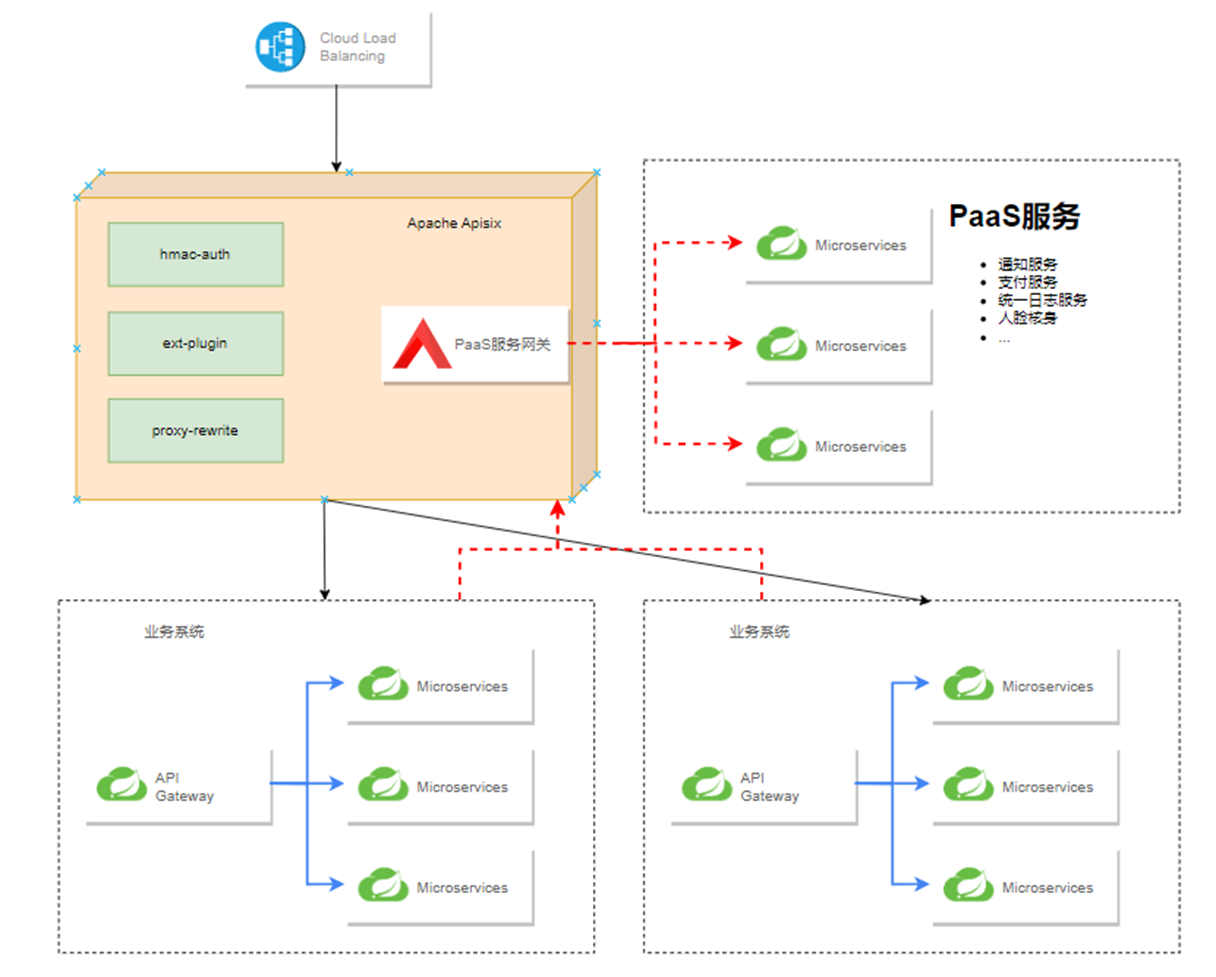
在安全控制这块,我们基于 APISIX 做了双层网关架构,在 APISIX 上隔离出一个逻辑网关,用户访问 CLB 进来 APISIX 再转发到业务系统;如果用户使用的这个功能需要用到 PaaS,就会通过 PaaS 服务网关进行访问,此时 PaaS 服务网关就是一个逻辑网关。
我们在 K8s 内部封闭了一个区域,即 PaaS 平台,里面包含大量的基础服务。利用 APISIX 网关的特性--熔断、安全、身份识别,使上层业务系统访问 PaaS 服务都需要通过 PaaS 网关。
流量管理
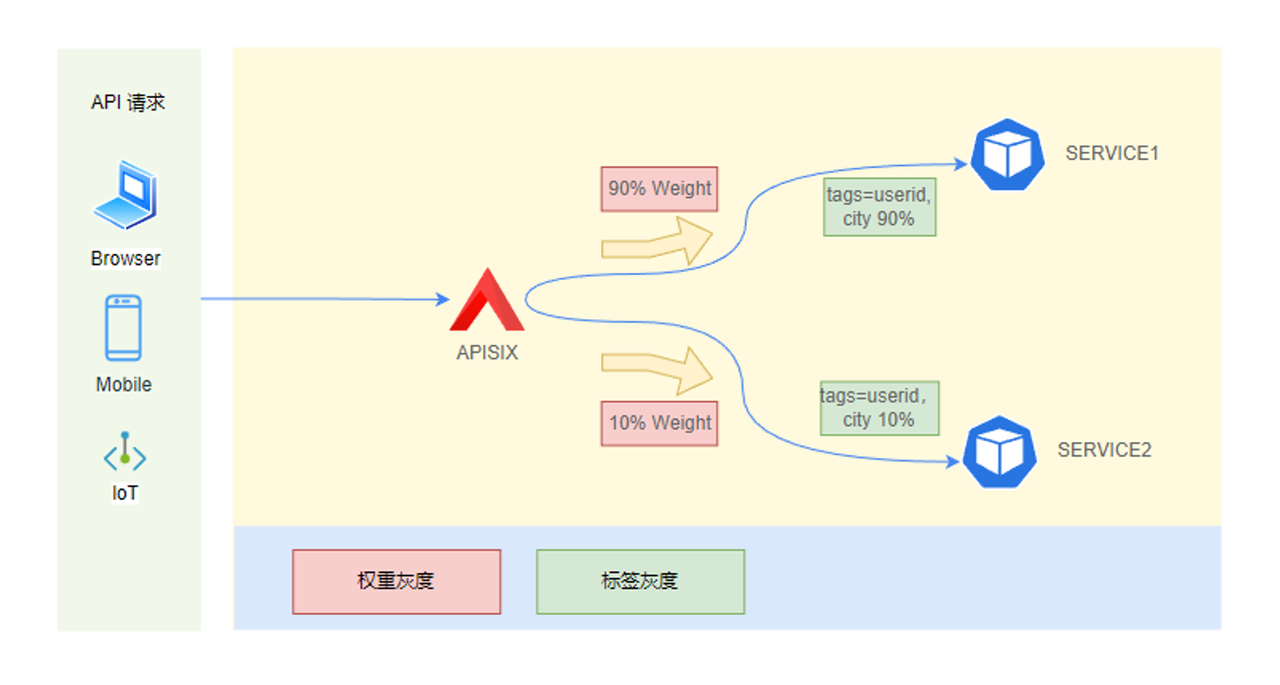
由于业务系统数量较多, 核心服务(SSO、PaaS 服务和发薪服务)可用性要求高, 这些服务的流量管控需要依赖 APISIX 提供的流量管理灰度策略。
为此,我们内部采用了两种方式进行。第一种是基于标签灰度, 核心服务上到生产环境之前,测试人员先在灰度环境验证,我们会将测试用户流量转发到灰度服务,进行生产环境验证;验证通过后再基于权重切入流量,观察一段时间,没问题后再把全部流量切换到新版本。 第二种是生产环境内,相同的服务并存多个版本,不同的业务系统访问不同的版本时,基于标签进行路由转发。
日志管理
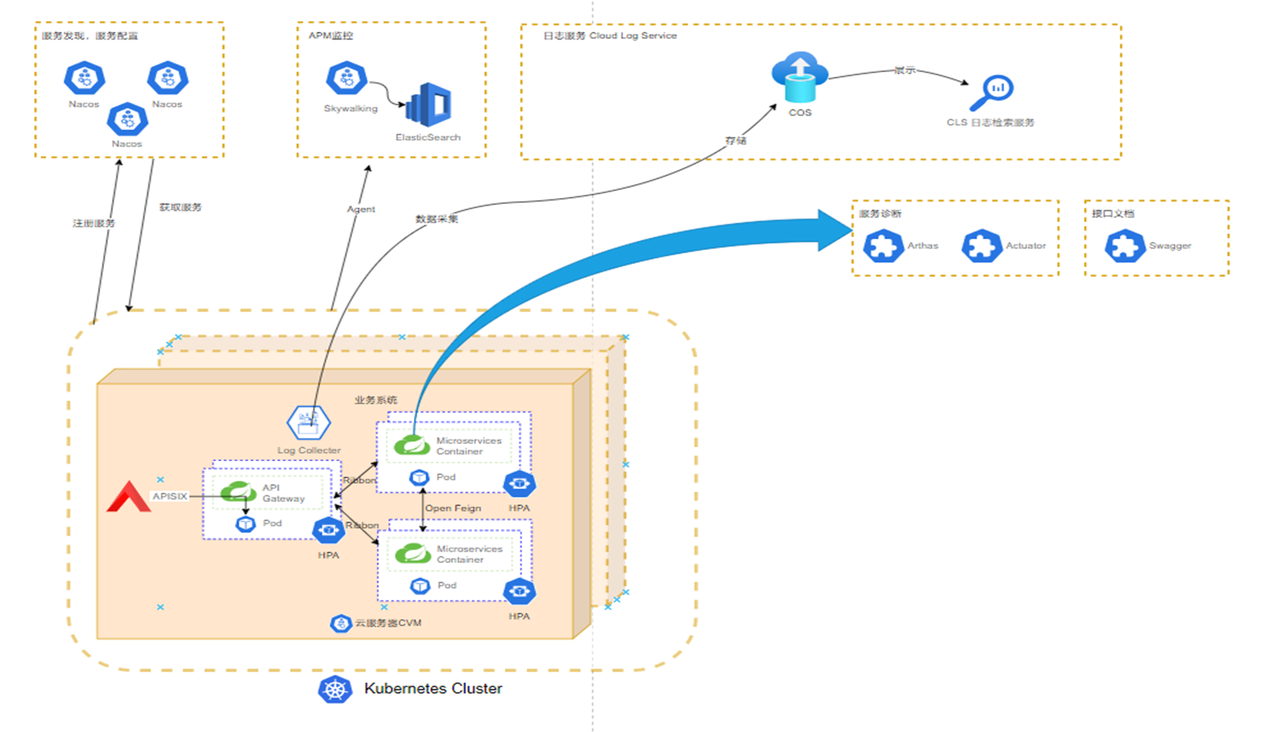
从上图的架构模式可以看出,APISIX 和 Pod 服务都基于 K8s 架构,所有后端路由都被绑定在同一服务上,在 APISIX 服务上配置的 Kafka 插件用来采集日志数据,同时配置了 Skywalking 监控程序性能。根据 RequestId 和 TraceId 在 Skywalking 和日志云,我们可以观测到整个调用链路,并查看每个环节的日志记录和 API 请求耗时。
从目前观测到的数据来看,系统每天都有上千万次的 API 请求,平均每天产生的日志数据达到 30G ,日志总量达到 TB 级。
使用 APISIX 的经验与展望
在使用 APISIX 的过程中,我们总结了一些经验之谈,在这里分享给对 APISIX 感兴趣的朋友们。
构建基础镜像需要拉取国外资源。由于我们 APISIX 需要部署在 K8s 内部,我们内部会进行一定的二次开发和源码编译,这时需要到 GitHub 上拉取资源,目前官方提供的 Docker 镜像有一部分需要拉取国外资源,在进行本地开发和线上部署时,环境调试相对麻烦。
调试环境部署有要求。自定义插件
java-plugin-runner,需要基于runner.sock进行 RPC 通讯,现有案例较少,调试起来有一定困难,它需要和 APISIX-Service 在同一个镜像内。每天产生大量的日志记录到本地。刚刚发布生产时,我们发现,就算只开启 error 级别日志,每天的增长数量都非常大,导致 K8s 集群中一个节点磁盘告警。后面我们打包镜像时将日志由文件记录改变为输出至控制台,收集至云日志服务 CLS 存储记录分析,实现本地无文件化存储。
当然,以上都属于前期准备工作上的必经之路,在正式投入使用后,APISIX 给我们带来的收益远远大于期望,总体有以下三点:
对业务发展起到了强有力的支撑。使用 APISIX 后,我们的系统功能更加丰富,性能更加强劲。APISIX 对 API 服务提供了多种可观测性和安全防护手段,可以支持我们每天千万次流量的访问。
助力研发交付效率。比如原来配置 DNS 解析需要 10 分钟才能生效,而现在通过泛域名配置,几秒钟就能生效;因为原先需要在 CLB 和 NGINX 两个地方手动修改配置,而我们有 10 多个系统、100 多个服务,需要配置的点很多,应用了 APISIX 的泛域名配置后,现在只需要在控制面板上修改,极大地减少 DevOps 工作量。
大幅降低成本。LB (负载均衡)成本的变化。LB 服务数量由 200+ 缩减到了 10+,大大降低了系统维护成本。
后期我们还会有一系列需要借助 APISIX 云原生网关达成的功能开发,包括但不限于集成 Sentinel 使服务具备热插拔动态限流功能、开发多维度流量控制、风控识别功能升级、分层治理和全链路日志分析等等。届时将采用多套 APISIX 集群来满足自研服务平台的功能需求。
所以说,使用 APISIX 云原生网关给我们技术带来了非常大的帮助,使我们能轻松应对多样化的复杂场景,打造趋于完美的数字化人力资源服务生态。