正则表达式的灾难性回溯(Catastrophic Backtracking)是指,正则在匹配的时候回溯过多,造成 CPU 100%,正常服务被阻塞。
背景
这里有一篇文章详细的描述了一次正则回溯导致 CPU 100% 的发现和解决过程,原文比较长,我之前也在 OpenResty 的开发中遇到过两次类似的问题。
这里简单归纳下,你就可以不用花费时间去了解背景了:
- 大部分开发语言的正则引擎是用基于回溯的 NFA 来实现(而不是基于 Thompson’s NFA);
- 如果回溯次数过多,就会导致灾难性回溯,CPU 100%;
- 需要用 gdb 分析 dump,或者 systemtap 分析线上环境来定位;
- 这种问题很难在代码上线前发现,需要逐个 review 正则表达式;
站在开发的角度,修复完有问题的正则表达式,就告一段落了。最多再加上一个保险机制,限制下回溯的次数,比如在 OpenResty 中这样设置:
1lua_regex_match_limit 100000;这样即使出现灾难性回溯,也会被限制住,不会跑满 CPU。
嗯,看上去已经很完美了吗?让我们来跳出开发的层面,用不同的维度来看待这个问题。
攻击者
只用一台机器,发送一个请求,就可以打跨对方的服务器,这简直就是黑客梦寐以求的核武器。与之相比,什么 DDoS 弱爆了,动静大还花钱多。
这种攻击也有自己的名字:ReDoS (RegEx Denial of Service)。
由于正则表达式应用非常广泛,几乎存在于后端服务的各个部分,所以只要找到其中一个漏洞,就有机可趁。
试想一个场景,黑客发现了 WAF 中存在 ReDoS 漏洞,发送一个请求打垮了 WAF;你无法在短时间内定位这个问题,甚至意识不到这是一次攻击;为了保证业务的正常,你选择重启或者暂时关闭 WAF;在 WAF 失效期间,黑客利用 SQL 注入,拖走了你的数据库。而你,可能还完全蒙在鼓里。
*由于开源软件和云服务的广泛使用,只保证自己写的正则表达式没有漏洞,也是不够的。*这是另外一个话题了,我们这里先只讨论自己可控范围内的正则。
如何发现这类正则表达式?
解决问题的第一步,就是发现问题,而且要尽量发现所有问题,也就是所谓安全的发现能力。
指望人工 code review 来发现有问题的正则,自然是靠不住的。大部分开发者是没有这方面安全意识的,就算有意去找,人也不可能从复杂的正则表达式中找到问题所在。
这正是自动化工具大显身手的时候。
我们有以下两种自动化的方法来解决:
- 静态检测
这类工具可以扫描代码中正则表达式,根据一定的算法,从中找出有灾难性回溯的正则。
比如 RXXR2,它是基于一篇 paper 中的算法来实现,把正则转换为ε-NFA,然后再进行搜索,但并不支持正则表达式的扩展语法,所以会有漏报。
- 动态 fuzzing
fuzz 测试是一种通用的软件测试方法,通过长时间输入大量随机的数据,来检测软件是否有崩溃、内存泄漏等问题。
同样的,在正则的测试中我们也可以用到这种方法。我们可以根据已有的正则表达式来生成测试数据,也可以完全随机生成。
SlowFuzz 是其中一个开源的工具,也是基于一篇 paper 的算法实现,本文最后会列出 paper,它是一个通用的工具,并没有针对正则的结构做处理,所以会有漏报。
SDLFuzzer 是几年前微软开发的一个专门的 ReDoS 检测工具,但已经不再维护了。
这方面的工具可选择的不多,而且关注度不高。不过让我兴奋的是,在搜索资料的过程中,发现了南京大学几位老师和博士关于 ReDoS 的一篇 paper,并且和 paper 一起开源了 ReScue 这个工具:https://2bdenny.github.io/ReScue/。这个工具已经找出了几个开源项目中的 ReDoS 漏洞。
下面是 paper 中对比测试的结果:
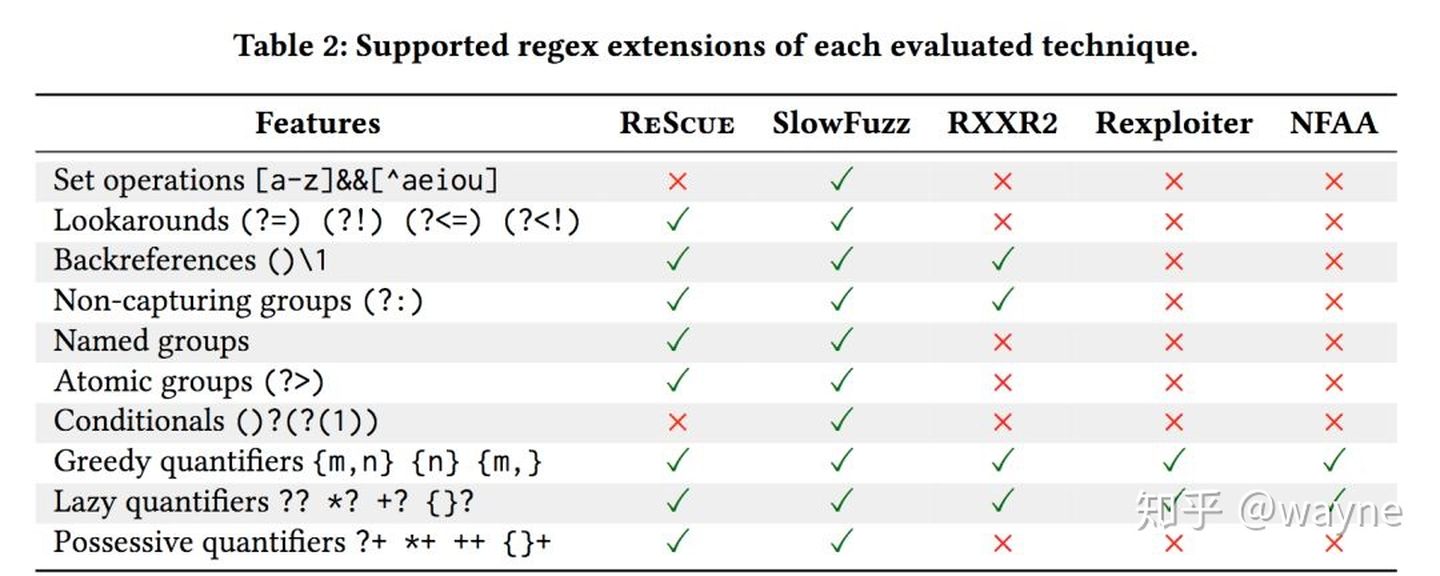
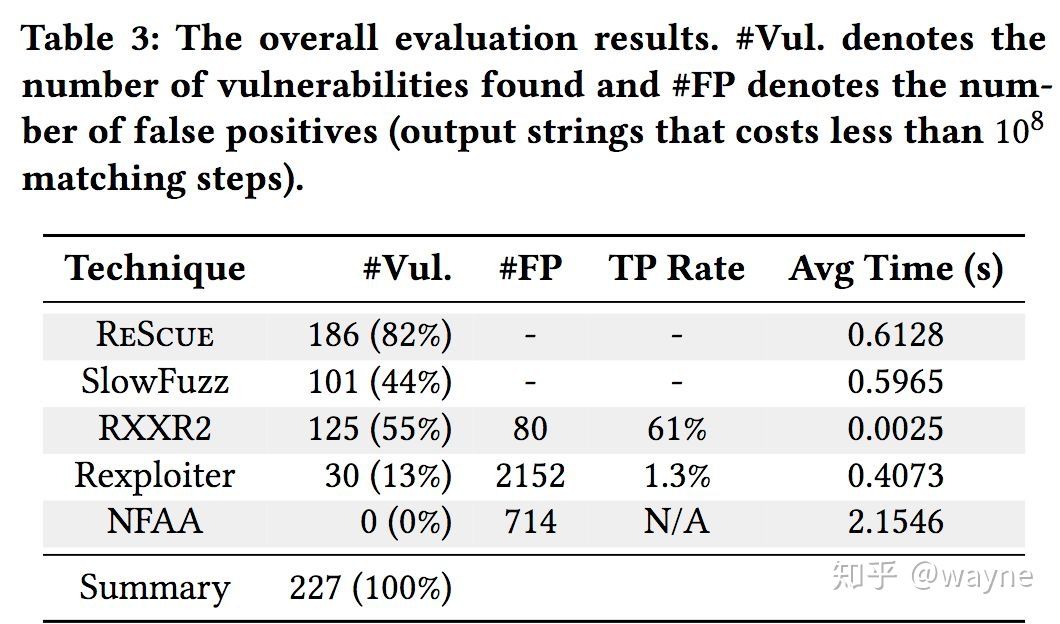
可否一劳永逸?
即使我们用了这类工具,有难免会有误报和漏报,那么有没有一劳永逸的方式来解决 ReDoS 呢?
那么我们就要回到问题产生的根源去寻找答案:正则引擎使用了回溯的方式来匹配。
如果我们弃用这种方法,是不是就可以了呢?没错,已经有不少其他的正则引擎的实现,都可以一劳永逸的来解决。他们都放弃了回溯,用 NFA/DFA 自动机的方法来实现,优点是适合流式匹配,也更加安全,缺点不支持很多正则的扩展语法,比如 backreferences,好在这些一般也用不到。
- Google RE2
谷歌的 RE2 是其中完成度比较高开源项目。它支持 PCRE 的大部分语法,而且有 Go、Python、Perl、Node.js 等多种开发语言的库实现,上手和替换成本很低。
我们以 Perl 为例,看下 RE2 是否可以避免灾难性回溯问题。
我们先来看下这个结果对比图:
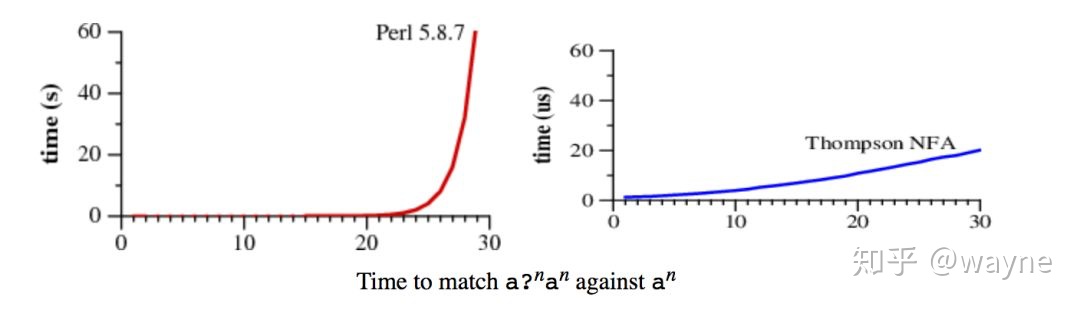
代码如下,感兴趣的可以自己试试看:
1time perl -e 'if ("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" =~ /a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/) {print("hit");}'
2
340.80s user 0.00s system 99% cpu 40.800 total
需要 40.8 秒才能跑完这个正则,期间 CPU 99%。
采用 RE2 之后,对比非常明显:
1time perl -e 'use re::engine::RE2; if ("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" =~ /a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/) {print(" hit");}'
2
3perl -e 0.00s user 0.00s system 34% cpu 0.011 total
- Intel Hyperscan
Intel Hyperscan 也是类似 RE2 的正则引擎,也有Perl、Python 等语言的库,上手难度不大。
只不过按照 Intel 的惯例,多了平台的绑定,只能跑在 x86 中。
如果非要说有什么独特的好处,可能是能够和 Intel 的指令集还有硬件更好的配合,有性能的提升,比如结合下自家的 DPDK。
开源的网络入侵检测工具 Snort,也用 Hyperscan 替换了之前的正则引擎,熟悉 Snort 的同学可以试试看。
扩展
这里有几篇正则表达式方面的 paper,感兴趣的可以作为扩展阅读。
[1] SlowFuzz: Automated Domain-Independent Detection of Algorithmic Complexity Vulnerabilities: https://arxiv.org/pdf/1708.08437.pdf
[2] Static Analysis for Regular Expression Exponential Runtime via Substructural Logics:https://arxiv.org/abs/1405.7058.pdf
[3] ReScue: Crafting Regular Expression DoS Attacks:https://dl.acm.org/doi/10.1145/3238147.3238159
[4] Regular Expression Matching Can Be Simple And Fast: https://swtch.com/~rsc/regexp/regexp1.html