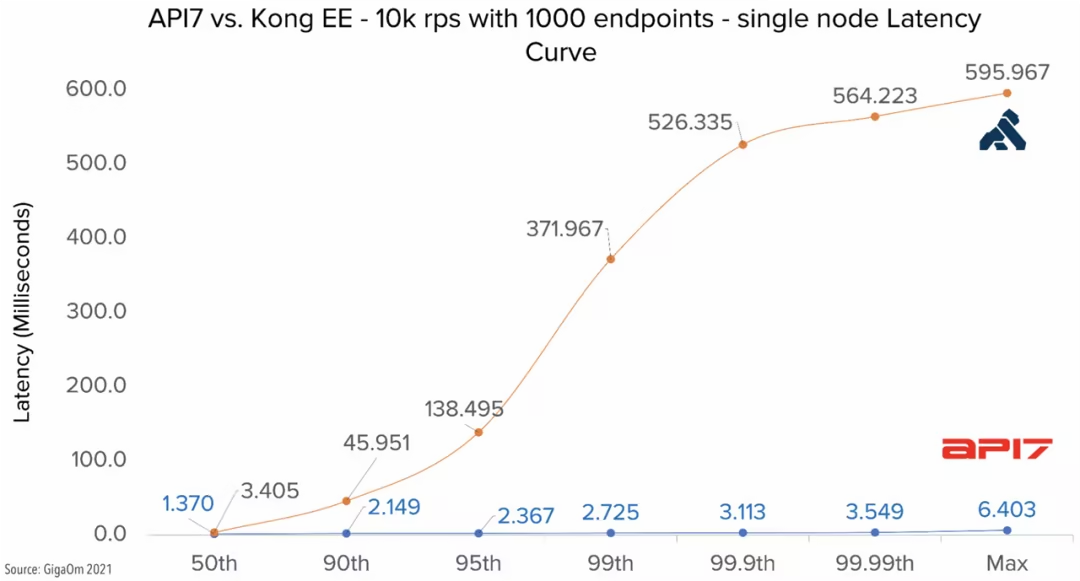
用户经常问到一个问题,即如何准确测量 APISIX 的延迟。当使用 APISIX 时,如果发现延迟异常高,应该怎么处理呢?
实际上,在讨论测量延迟时,我们实际上是关注 API 请求的性能和响应时间。了解这些方面对确保高效的 API 服务非常重要,尤其是在 B2B 软件中,因为客户对 API 的可用性和性能要求很高。在一些敏感的场景中,比如股票交易市场中的交易软件,延迟会对交易者产生巨大的影响。
那么,什么是延迟?在 APISIX 中,延迟又指什么呢?让我们首先明确一下它的含义。这里的延迟实际上指的是 API 请求从客户端发送到接收响应的整个过程所花费的时间。这个延迟可以由多个因素构成,包括客户端网络延迟、APISIX 内部处理时间以及与上游服务的交互延迟。
为了更好地理解和测量这些延迟,我们可以将其分为几个关键的部分。
第一个部分是指客户端到 APISIX 之间的网络延迟,即当一个请求从客户端发送到 APISIX 时,在此期间所耗费的时间。它会受到客户端和 APISIX 之间的距离、网络阻塞等因素的影响。我们可以通过一些专门的工具来测量耗时。
第二个部分是指 APISIX 内部处理的时间。因为当请求到达 APISIX 内部时,它需要在 APISIX 中完成一系列的逻辑,同时 APISIX 有很多的插件,包括路由决策、认证授权、流量管理等自定义逻辑,这些操作执行的时间被称为 APISIX 的内部处理时间。
第三个关键部分是与上游服务的交互延迟。如果 APISIX 需要与上游服务(通常是后端应用程序或一些微服务)进行通信,那么与上游服务的交互延迟也会被计入总延迟中,包括请求从 APISIX 发送到上游服务以及响应返回的时间。
那么如何测量 APISIX 的延迟呢?我们可以按照 “APISIX 的延迟 = 总延迟 - 上游交互的延迟” 这个公式进行计算。其中,总延迟指的是从客户端发送请求到接收响应的整个耗时,而上游延迟指的是 APISIX 与上游服务,如后端应用程序进行通信的耗时。根据这个公式,我们就能计算出 APISIX 的延迟,并判断到底是不是因为 APISIX 产生了高延迟的问题。这有助于我们了解请求的性能和各个组成部分的耗时情况。
说明:在 Linux 系统上,
upstream_response_time是通过clock_gettime(CLOCK_MONOTONIC_COARSE)来计算的,而在CONFIG_HZ=250的配置下,其精度可能达到 4 毫秒。与此同时,request_time的计算时间并非单调递增的时间,而是基于gettimeofday()函数获取的挂钟时间。因此,在某些情况下,upstream_response_time可能会略大于request_time。另外,在弱网环境、大文件上传下载等场景下,客户端与网关之间的延迟会被计入
apisix_latency中。请针对具体情况进行具体分析。
具体的 APISIX 的延迟又可以进一步分为三类。
第一类指的是下游的延迟,其中包括了 APISIX 与客户端之间的网络传输延迟、读取请求体等操作的耗时。如果传输了一个很大的请求体,那么势必会增加延迟时间。通过监控和分析这个延迟,我们可以了解到客户端到 APISIX 之间的通信性能,并进行必要的优化。
第二类指的是 NGINX 延迟,在 APISIX 中我们使用了 NGINX 来处理请求和路由,因此 NGINX 的内部运行时间也会影响总延迟。这可以通过专门的工具进行监测。
第三类指的是 Lua 插件代码执行的延迟,因为 APISIX 有许多的 Lua 插件,每一个插件执行的时间也是一个重要的延迟因素。我们同样需要专门的工具进行分析。
那么如何解决这些延迟呢?通过刚才提到的一些延迟的情况,我们可以通过排除法逐一分析。
如果是因为客户端网络延迟,我们就可以通过优化网络架构、使用 CDN 等方式来降低延迟;针对 APISIX 内置的 Lua 代码,如果运行耗时过长,那么我们就需要找出到底是哪一个插件的哪一部分代码引起了延迟;有关与上游服务交互相关的延迟,我们就需要检查与上游服务交互到底有多久,然后检查上游服务是不是有阻塞性代码或者是 APISIX 到上游服务之间的网络受到了影响。通过优化这些点,我们可以降低一定的延迟情况。
最重要的是,持续监控和分析 APISIX 的延迟能够方便我们及时发现和解决潜在的问题。通过深入了解各个组成部分,可以更好地优化 API 的服务,提高可用性和响应性,更好地满足终端客户的需求。
有关 QPS 和延迟,APISIX 和与其他网关产品的对比数据可阅读:为什么 Apache APISIX 是最好的 API 网关?。